To get everyone up to speed, here’s the straightforward approach to calculating CPV:
Imagine that you’re running a race for school board and you want to use some of the money in your campaign coffers to turn out some voters. You decide to send mail, but since you want to learn something for your future campaigns, you hold out a control group. You send 1,000 pieces of mail to a random selection of voters and don’t send mail to a control group of the same size. On election day 540 people who received your mail voted and 520 people in the control group voted. This gives you a treatment effect of 2% (+20 votes / 1000 people.) Now suppose that you paid $500 to send those 1000 pieces of mail: you wind up with $500 / 20 votes: which is a cost per vote of $25.
Now that we're on the same page about what CPV is, it’s time to tear it down so we can build it back up. First, we have to understand cost per vote in the context of winning an election. The goal of optimizing around CPV is not to find the intervention that nets you the most votes for the fewest dollars, but rather to assemble a set of interventions that get you to a win as cheaply as possible. This is a hugely important distinction and where a lot of tacticians get hung up. Below are some examples that help to highlight this distinction and get you thinking in CPV:
Never gonna win:
Imagine that you’re a Democrat running for congress in Wyoming where in 2018 the Republican won by more than a 2:1 margin (127k votes for the Republican to 60k votes for the Democrat) Now let's say that you have some absolutely killer intervention that gets you 100 votes for $5. That’s not to say that for every $5 you put into the machine you get 100 votes, but rather that you have an intervention that you can deploy once that will cost $5 and will generate 100 votes. A CPV of $0.05 is unheard of and seems like a no brainer, but if you go from losing by 68k votes to 67.9k votes you still lose the election by a wide margin. Does this mean that the $5 was wisely spent or no?
The close but not so close case:
Imagine now that you’re a Republican staffer working in a competitive senate election against an incumbent Democrat. All of the signs point to your state being one of the most competitive races on the map. Because this is going to be such a close race, you deploy every tactic that you can think of since it’ll come down to a narrow margin. You even hold out a control group and measure the effect sizes of your interventions so you can evaluate everything after the race. Then your candidate says something monumentally stupid-- like the kind of stupid that operatives will talk about eight years later-- and support for your candidate drops by 10 percentage points. This drop moves everyone you persuaded back to supporting the Democrat and a whole bunch of other voters move away as well. Did the CPV on the tactics you deployed change? Was this a wise investment at the time you made it?
The truly close race:
Now let's think about a race where the bottom doesn’t fall out. The race is close and stays close. In fact, it’s so close that it’s won by exactly 1 vote. Just like the previous example, you deployed all of the tactics and after the election you have a range of CPVs for your tactics. If you were able to generate 100 votes for an investment of $1,000 in digital ads and you were able to generate another 100 votes from an investment of $10,000 in direct mail, would you go back and spend all the money that you spent on direct mail in digital ads? Should we say that direct mail is a worse investment than digital ads?
The chopping block:
Finally let's imagine that you’re a campaign manager in a competitive race and you’re responsible for the campaign’s budget. You have $35,000 that you can use to add to a flight of persuasion mail you’ve already tested or you can hire a press assistant. The value of the mail is known-- you tested it and that additional $35,000 will generate 700 votes (CPV of $50) and the value of a press assistant (in terms of votes) is unknown, but relationships with journalists will suffer and this might result in your candidate being portrayed less favorably in the media. This will cost you votes, but how many votes it will cost you is unclear. What’s the better bet, and how would you make the call?
Diminishing Returns and CPV
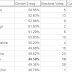
Next, let's talk about diminishing returns on tactics. We don't know the exact function for diminishing returns on campaign interventions, but we’ve got a reasonable idea about the shape of the curve. I’m going to present 4 campaign tactics and show how even when we start with wildly different CPV for the first intervention we want to start mixing in other tactics pretty quickly.Here I’ll assume that every tactic has the same diminishing returns rate and they all follow the function 1/(2^n) * ATE (average treatment effect.) If we start with the following assumptions about cost and effect size for each tactic, we get CPV curves in the chart below:

Now the effect sizes and costs are going to be off here, but the general shape of what’s going on should be consistent with what someone doing this with a richer data set. There is a really wide gap for the first intervention between expensive and cheap tactics, but pretty quickly the first intervention at an expensive tactic starts out-performing additional interventions on the cheap tactics.
If you want to be a stickler about this, the diminishing returns curves probably re-start for every new piece of creative (e.g. a new mailer or a new tv/digital ad) but in my experience even with new creative, we are still subject to diminishing returns within any mode, though we move more slowly up that curve if creative is changed more frequently. My best guess here is that there’s a ceiling on application (e.g. many people don’t read their mail or use an ad blocker) and another ceiling on new information (e.g. once someone has heard a thing before, the next intervention is met with “i know that already!”)
The Ark and the Clown Car
Ok so now that we’re stuck in nihilistic impotence, it’s time to talk about how to actually make decisions using CPV. As I discussed in the “never gonna win” scenario (and will continue to discuss at every opportunity,) the driving factor for everything is whether or not the race is competitive. If the race will not be competitive, your CPV does not matter because elections are winner-take-all. If you’re coming from commercial marketing, increasing market share from 25% to 30% is as good as increasing market share from 47.5% to 52.5%, but in elections those are worlds apart. So we’re only talking about competitive races.Now that we are in the world of competitive races, the next thing to consider is budget. As we saw in the “close but not so close” example, you’re going to deploy your budget as if your race was close and hope for the best. This means that you’re not setting some vote goal based on where support is right now and asking what tactics you use to get close the gap and reach your target number of votes. There might be big shocks that cause swings in support levels, so building from a top-down approach like “we need to generate 8,000 votes to secure a win” is just going to lead to weird and brittle decisions. So now we’re to a point where we’re talking about competitive races and starting from a budget.
Once we have our budget, the goal is to assemble a set of interventions that will deliver the most votes. This is where the decisions are going to be driven more by judgement than by formal evidence, but I’ll try to describe how to navigate them. The most principled approach I can come up with is by dividing expenditures into ones that are subject to diminishing returns and ones that benefit from increasing returns. Things like door-to-door canvassing, direct mail, and other direct marketing tactics all seem to be subject to diminishing returns. Things like opposition research, flacking, and community organizing seem to benefit from increasing returns. My best guess about why this happens is that the direct marketing tactics are unable to benefit from network effects because they’re delivered in an atomized way that doesn’t allow for communication around a shared experience (just a guess though!)
So we’ve got these two bins-- interventions that are subject to diminishing returns and interventions that benefit from increasing returns. We’ll start with the diminishing returns bin, where we should check all the boxes at low levels. That means doing a little bit of everything to make sure that all of our interventions are at their most potent. Specifically this means that if the budget allows it, every reasonable tactic should be on the table for it’s first pass. We should then move up our CPV curve for each of the cheapest tactics until we have matched the CPV of our most expensive tactic’s first pass because by investing in the most expensive tactic we're stating that we're comfortable with a CPV that's at least that high. Using the interventions from our diminishing returns curve above, that means our budget would look like:
Here our marginal CPV is our CPV for the last application before we cross over into our next most expensive tactic. So the first GOTV mailer had a CPV of $35 and the second one had a CPV of $70. Just to be very explicit about this, I’m not recommending this exact mix-- mixing depends on more robust diminishing returns calculations by mode, more precise estimates of ATE and the best price you can get for your interventions. I’m only using these made up data as an example. What’s essential to understand here, though, is that campaigns benefit from a diversity of tactics. This should be like Noah’s ark-- don’t bring a lot of anything, but get as many different species on as possible.
Once we get out of direct marketing tactics, things get a lot more complicated. Funding the increasing returns bins is largely untouched in the academic lit, but if you ask experts things like campaign communications, research, and community organizing are among the most essential components of an election. Interventions in these bins should look more like a clown car than the ark-- pack as many people in as possible until no else can fit.
So when we're building our budget we start by checking all the boxes for our tactics and filling up on them until we start getting crushed by diminishing returns and then pack all the rest of the money into the clown cars.





{kind=link}